
What is the Flux
Application Architecture?
Flux is an idea for organizing your application that was developed at Facebook, based on one simple principle:
Data moves in one direction through your application.
This is called “unidirectional data flow”, but it might be easier to remember if you think of your data as a shark: Sharks can only swim forward.
Facebook has published examples of Flux, and at least six other libraries have sprung up with interpretations. For the purpose of this article, when we say “Flux”, we are referring to the Facebook implementation.
A Flux Example
To understand Flux, let’s walk through a basic Todo application. You can find the full source code in the Facebook Flux Repository.
Loading the ToDo Items

When the application starts, the ToDoApp React component fetches and displays the data that is present in the ToDoStore. The ToDoStore is completely unaware of the ToDoApp component. If you imagine the component acting as a View, and the ToDoStore as a Model, then so far this isn’t so different from MVC.
In this simplified example, we aren’t worrying about how the ToDoStore loads the initial data.
Creating a New ToDo Item

The ToDoApp Component has a form for creating a new ToDo item. When a user submits that form, it kicks off a flow of data through the Flux system, as illustrated above:
- The component handles the form submission by calling its own callback.
2. The component callback calls a method on the ToDoActionCreator.
3. The ToDoActionCreator creates an action of the type TODO_CREATE.
4. The action is sent to the Dispatcher.
5. The Dispatcher passes the action to all registered callbacks from Stores.
6. The ToDoStore has a registered callback that listens for the TODO_CREATE action, and updates its own data.
7. The ToDoStore fires a change event after updating its data.
8. The ToDoApp component is listening for change events from the ToDoStore, and re-renders the UI based on the latest data from the ToDoStore.
Flux vs. MVC
Flux has been presented as an alternative to MVC. The documentation for Flux explains that it “eschews MVC in favor of a unidirectional data flow”. When comparing Flux to MVC, you have to understand three things:
- “MVC” actually means “MV*” in the land of JavaScript.
- Flux is not simpler than MV*.
- Flux keeps things more predictable than MV*.
“MVC” actually means “MV*” in the land of JavaScript.
In order to compare Flux to MVC, we need to understand what MVC means in this context.
There are 15 examples of JavaScript frameworks on ToDoMVC, but none are strict implementations of the “Model, View, Controller” design pattern. Take Backbone.js as an example: It has models and views, but there is arguably no controller in Backbone.js. The role of the controller in many JavaScript frameworks is absorbed into the view or model, and there may be other important categories of functionality, such as a router.
When we use “MVC” or “MV*” to describe a JavaScript architecture, we generally mean that it has a separation of concerns when dealing with business logic and user interfaces. The data storage is compartmentalized into “models”, while the presentation and user interactions are dealt with in “views”.
This might work as follows: the view gets information from the model and displays it to the user. The user then interacts with it. These interactions trigger the view to update the data stored in the model, which then may trigger a UI update in the view.

Flux is not simpler than MV*.
You may have watched the Facebook intro to Flux and seen the analysis of why “MVC doesn’t scale”, including a diagram showing the flow of data amongst 7 different models and views:
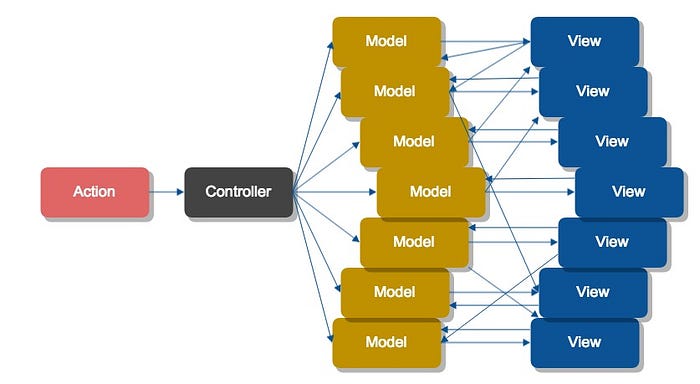
This makes MVC look super confusing — look at all those arrows! Who can follow what’s going on in that diagram? It seems obvious that Flux is simpler, right?
But in that video we never get to see the same level of complexity implemented in Flux. Sure, it all “collapses down” to a simple flow of data:
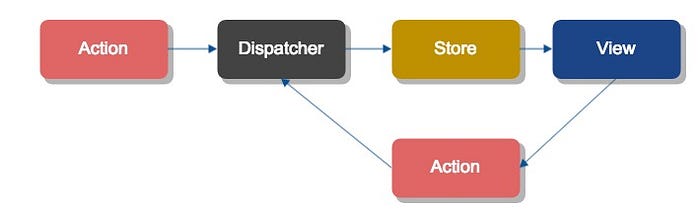
Still, it is worth seeing what a large system implemented in Flux would look like. Here it is, and you’ll notice that there are more arrows and boxes than the MVC version, not fewer:
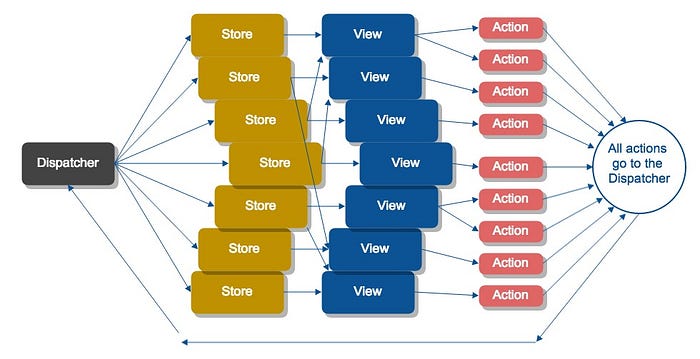
Flux has just as many moving parts as MV*. That is why this diagram looks just as complex as the MV* diagram — but with one key difference: The arrows point in one direction, forming a consistent cycle through the system.
Flux keeps things predictable.
There are many things going on in both the Flux and the MV* diagrams — but the level of predictability in the Flux diagram is much higher.
The dispatcher in Flux also ensures that the actions flow through the system one at at time. If an action is sent to the dispatcher before it is finished processing an existing action, it will throw an error:
“Uncaught Error: Invariant Violation: Dispatch.dispatch(…): Cannot dispatch in the middle of a dispatch.”
This is another way of keeping things predictable. It pushes developers to build applications without complicated interactions between data resources.
The dispatcher also allows the developer to specify the order that stores execute their callbacks, using the waitFor method to tell one store to wait for another before executing its callback. If you write code where two stores waitFor each other, then the dispatcher throws an informative error.
In the Facebook implementation of Flux you can see exactly what causes data to change. Every store includes a list of actions it listens to.
In this example, the ThreadStore listens to the CLICK_THREAD action and the RECEIVE_RAW_MESSAGES action. If the store is not updating as expected, the register callback gives us a place to start debugging. We can log any actions it receives and inspect their payload of data.
Similarly, every component maintains a list of which stores it listens to.
Above, we see the ThreadSection component listens for changes in the ThreadStore and the UnreadThreadStore. If we consistently use this method for setting up listeners in the components for changes in the stores, then we can be sure that no other stores will affect the behavior of this component.
Flux separates the concerns of receiving and sending data, so that when debugging you can easily follow the flow of data to see where things may be going wrong.
Difficulties of Flux
Every choice in software engineering is a trade-off, and Flux is no exception. We have perceived the following disadvantages:
- It involves writing more boilerplate code
- Migrating existing resources can be a big task
- Unit testing can be difficult without good structure
Flux does add more files and more lines of code than one might feel are needed to handle the flow of data in an application. This will be more painful when writing fresh code for a new data resource, rather than adding code for a resource that already uses Flux. In the future we may have generators to make the set-up of Flux faster. Using Vim snippets can also speed things up.
The easiest way to try Flux is with a new project. With anything new, getting others on board can be a challenge. This post, along with the documentation and examples from Facebook, will give you the knowledge needed for educating others. You can be confident that if Facebook and many other companies are using Flux for production code, in projects large and small, then it will scale for your project too.
When migrating an existing application to Flux, you can try out the Flux architecture with one data resource at a time. However, when considering using Flux to manage a piece of data in your application, think about how many components use that piece of data. If it is used in most of your components, then it could be a big job to move the management of that particular piece of data to Flux. Start with a more isolated piece of data when first trying Flux out.
With Flux your components start depending on ActionCreators and Stores as well as their usual dependencies on each other. This can make it more difficult to write unit tests. If you restrict the interaction with Stores to the top level “controller” components in your application, then you can unit test the child components without worrying about the Stores. For testing components that do need to send Actions and listen to Stores, we have had some success with mocking the Store methods, or mocking the API responses that the Actions and Stores use to get data.
Have you tried Flux?
At Brigade, we have learned from the experience of moving to a Flux approach. Have you tried Flux? Have you run into any difficulties, and how have you solved them? I look forward to seeing more examples and discussion of Flux in the future.
If you haven’t worked with Flux, then I hope this post gave you some insight into this approach to organizing an application.
